
下面以最常用的R语言为例,解析Apriori算法的基本分析思路。
R 语言中关于关联分析的开发包非常丰富,有arulesCBA、arulesNBminer、Opusminer、RKEEL 、arulesSequences、RSarules等,这里主要以基础的arules、arulesViz等开发包
及其包含的Groceries数据集为示范,介绍Apriori算法的关联分析步骤。
下面范例使用的是R version 4.1.2(RStudio)开发环境。
1、#载入算法包及购物篮数据库
>install.packages("arules") #安装Apriori算法程序包
>install.packages("arulesViz") #安装Apriori算法可视化开发包
>library(arules) #载入关联规则包
>Library(arulesViz) #载入关联规则的数据可视化
>Library(RColorBrewer) # 载入图形调色板
>data(Groceries) #调用R自带超市数据集Groceries
2、对Groceries数据集进行观察:
>print(levels(itemInfo(Groceries)[["level1"]])) # 查看Groceries数据库一级商品品类,显示如下:
[1] "canned food" "detergent" "drinks"
[4] "fresh products" "fruit and vegetables" "meat and sausage"
[7] "non-food" "perfumery" "processed food"
[10] "snacks and candies"
# 显示结果表示Groceries数据库共有10个一级品类,即罐头食品、洗衣液、饮料、生鲜商品、果蔬、肉和香肠、非食品、香水、加工食品、零食和糖果;
>print(levels(itemInfo(Groceries)[["level2"]])) #查看Groceries数据库的二级品类,显示如图3-1

图3-1 Groceries数据二级品类分布
# 如图3-1所示,Groceries数据库共有二级品类55个,第一个二级品类是儿童食品、最后一个(第55个)二级品类为葡萄酒。
# 这55个二级品类归属于上述10个一级品类,比如二级品类bread and backed goods应该归属于一级品类processed food,而二级品类 fruit 应该归属于一级品类fruit and vegetables,二级品类beer、wine、tea/cocoa drinks应该都归属于一级品类drinks,以此类推。
# 在Groceries数据库中,购物篮中的商品由169个商品组成,购物篮商品是二级品类下属的细分品类,并不是现实中的超市售卖具体商品,按照上述查看命令查看level3并不能看到细分的169个商品品类。
> summary(Groceries) # 查看Groceries数据库概况,显示图3-2
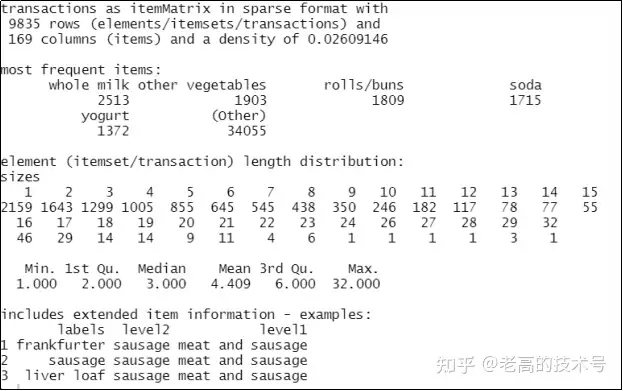
图3-2 Groceries数据库概述图示
# 如图3-2 所示,Groceries数据库共有9835条交易(购物篮),由169个商品(细分品类)完成,交易中出现次数最多(most frequent items)前6个商品依次为全脂牛奶(whole milk)为2513次、其他蔬菜(other vegetables)为1903次、圆面包(rolls/buns)为1809次、苏打水(soda)为1715次 、酸奶(yogurt)为1372次、其他商品:34055次;商品在购物篮数据库中出现的次数顺序对应了超市中顾客最关注的商品顺序,类似于购物篮渗透率PI值。
# 图3-2中所示的的“element (itemset/transaction) length distribution:sizes”是购物篮交易数据库中购物篮系数的分布,即购物篮中有几个商品品种。
# 从图3-2中看到,在交易数据集的9835个购物篮中,购物篮系数为1的交易数为2159、购物篮系数为2的交易数1643、购物篮系数为3的交易数为1299,以此类推,最大的购物篮系数为32,交易数量为1。
#图3-2 显示了9835笔交易的购物篮系数统计学意义四等分数分布,如下所示:
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 2.000 3.000 4.409 6.000 32.000
Min. 1st Qu. Median Mean 3rd Qu. Max.,
#含义如下:最小值为1.000,第一四分位数(1st Qu.)为2.000,中位数(Median)均值为3.000,第三四分位数(Mean 3rd Qu.)为4.409,最大值的(Max.)为32.000,中位数代表了Groceries数据库的购物篮系数平均值为3.0。
# 图3-2中的“includes extended item information - examples:” 说明了本数据库的一、二级品类,并进行了三个二级品类的归属一级品类示例说明,比如二级品类frankfurter sausage(法兰克福香肠) 属于一级品类meat and sausage(肉类和香肠),二级品类sausage(香肠)也属于一级品类meat and sausage(肉类和香肠),以此类推。
>inspect(Groceries) #查看Groceries数据集中的全部购物篮记录,这条指令可以列出Groceries数据库中的全部购物篮明细数据(显示结果略)。
> inspect(Groceries[1:5,]) # 列出Groceries数据库的前5个购物篮数据,显示如下:
items
[1] {citrus fruit, semi-finished bread, margarine, ready soups} #【1】是购物篮的序号
[2] {tropical fruit, yogurt, coffee} # {购物篮中的商品构成};
[3] {whole milk}
[4] {pip fruit, yogurt, cream cheese , meat spreads}
[5] {other vegetables,whole milk, condensed milk, long life bakery product};