
紫东.太初再进化,揭秘全模态大模型的想象力
2023年05月10日
评论数(0)
半个月前的一场内部分享中,奇绩创坛创始人陆奇直言:他已经跟不上大模型时代的“狂飙”速度了。
在ChatGPT引发的现象级讨论下,千亿级大模型的军备竞赛愈演愈烈,不少企业赶趟儿式的交出了自家的大模型答卷。尽管大模型的质量参差不齐,却再一次诠释了“量变引起质变”的哲学规律。
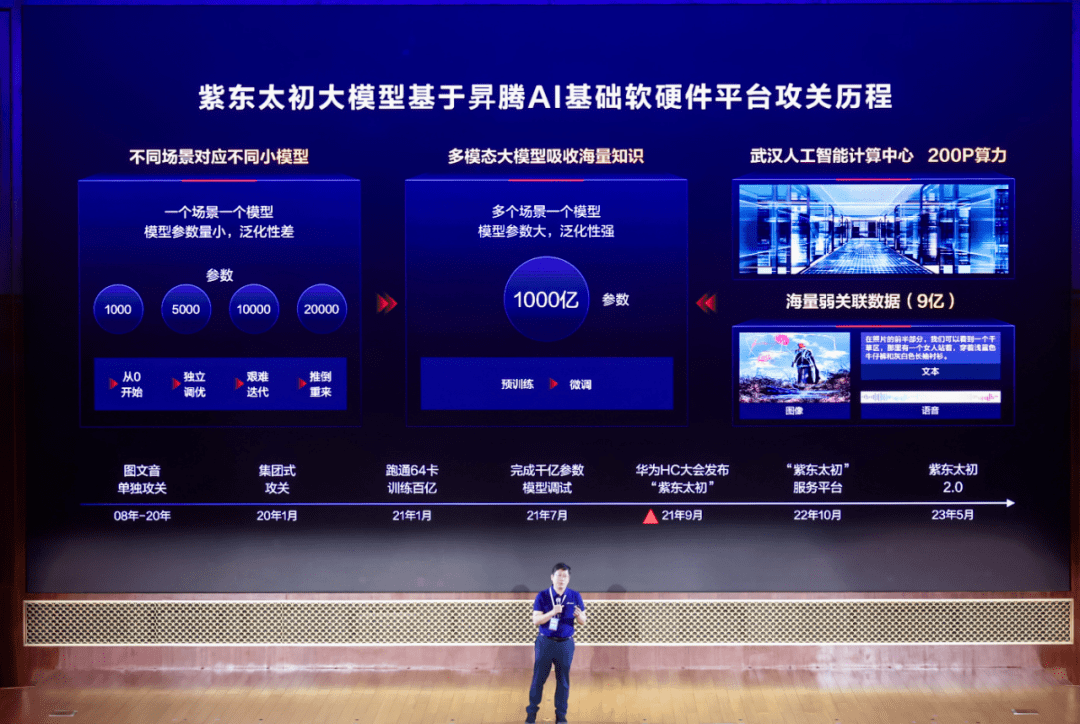
日前结束的昇腾AI开发者峰会2023上,中国科学院自动化研究所“紫东.太初”大模型研究中心常务副主任、武汉人工智能研究院院长王金桥在演讲中介绍了基于昇腾AI与昇思MindSpore AI框架打造的全模态大模型紫东.太初2.0,并首次提出全模态多任务统一生成式学习框架。
借用Hugging Face联合创始人Thomas Wolf的说法:“在过去的几年里,好的多模态模型一直是许多大型技术实验室的圣杯。”当大模型进入到全模态时代,将对整个产业链带来哪些影响?
01 什么是全模态大模型?
以往提到大模型的时候,最惹眼的名词无疑是“参数”,从1.1亿参数的GPT到1750亿参数的GPT-3,千亿级参数几乎成了大模型的“准入门槛”,毕竟模型的参数量越大,泛化性可能就越强。
其实还有另外一种分类标准,即模态,分别对应单模态、多模态、全模态等不同类型,比如一鸣惊人的GPT-3就属单模态大模型,紫东.太初1.0和GPT-4属于多模态大模型,紫东.太初2.0是全球首个全模态大模型。
至于其中的差别,可以从三个维度进行拆解:
首先是原理。
所谓的模态,即大模型可以处理的数据类型。单模态大模型只能处理一种类型的数据,也是出现语言、语音、视觉等不同模态大模型的原因所在,就像GPT-3系列就只有处理自然语言的能力。
顾名思义,多模态大模型意味着可以处理多个模态的数据,比如首个三模态大模型紫东.太初1.0,可以利用文本、图片、音频三种模态数据进行跨模态的统一表征和学习。对应到全模态大模型,泛指可以利用文本、图片、音频、视频、3D等不同模态的数据进行跨模态的统一表征和学习,更接近人类的学习方式。
其次是成本。
ChatGPT刚刚走红的时候,不少人在讨论OpenAI的训练成本,据悉GPT-3训练一次的硬件和电力成本高达1200万美元,由此出现了这样一种流行说法:每一个大模型都是一台昂贵的“碎钞机”。
有别于单模态大模型的是,紫东.太初1.0代表的多模态大模型,通过建立弱关联多模态数据语义统一表示,支持三种或任两种模态数据混合训练,进而减少了数据收集清洗的代价;到了全模态大模型阶段,紫东.太初2.0的一个鲜明特点在于全模态低成本协同优化学习,能够融合多任务全模态能力,进而降低训练成本。
最后是能力。
大模型领域有“大力出奇迹”的信仰,根源在于大模型的“涌现”现象,当大模型的参数量超过某个阈值(一般说法是参数量达到600-1000亿),模型会出现一些意想不到的复杂能力,譬如类似人类的思维和推理能力。
正如前面所提到的,紫东.太初2.0首次提出了全模态多任务统一生成式学习框架,即全模态分组对齐、分组解码和联合解码的学习方式,形成了全模态逻辑推理链。而跨模态迁移更有利于知识获取,产生更多新的能力,紫东.太初2.0有望加速能力涌现,进一步突破感知、认知和决策的交互屏障。
相较于比拼参数、算力和数据的“大模型炼丹术”,由单模态到多模态再到全模态的进化,可以自动学习到复杂的特征和模式,实现更准确和更高效的预测和决策,同样是走向通用人工智能的必由之路。
02 大模型为何需要开源?
如果说“全模态”是紫东.太初2.0的第一个闪光点,另一个值得关注的消息是:紫东.太初2.0-3.8B模型已经在昇思MindSpore社区开源,相比于紫东.太初1.0,支持更细粒度的图像识别、更具知识的视觉问答、更丰富的图像描述。
似乎有必要重温下开源和闭源的故事。
1997年,著名黑客埃里克·斯蒂芬·雷蒙在《大教堂与市集》一书中预测了两种不同的自由软件开发模式:一种是大教堂模式,原始代码是公开的,但每个版本的开发过程由一个专属的团队管控;一种是市集模式,原始代码同样是公开的,不过是放在互联网上供人检视及开发,最直接的例子就是Linux。
最终“市集模式”证明了开源比闭源更加高效,全球99%的组织在IT系统中使用了大量的开源代码,开源的价值也被越来越多的企业重视。

2020年以前的时候,OpenAI信奉的也是开源策略,但在商业利益的诱惑下,GPT-3选择了闭源,只针对开发者提供API,OpenAI由此被戏称为ClosedAI,以至于国内的几家大模型厂商也选择了API模式。
再来理解紫东.太初系列大模型在昇思MindSpore社区开源的现实意义,或许可以找到一些不同的答案。
一是价格层面。开源没有所谓的许可或使用费,只要有足够的算力和数据,就可以在昇思社区上下载紫东.太初2.0-3.8B训练自己的大模型。而闭源的成本取决于软件的规模,目前OpenAI的ChatGPT API的最新接口调用费是每千次token约0.002美元,折合人民币0.014元,还是多次降价的结果。
二是安全层面。开源软件有一个完整的社区来审查代码,而闭源是由单一平台负责修改漏洞,出现了错误可能无法被及时改正。况且大模型的安全问题远不止于此,据传三星电子引入ChatGPT不到20天时间,就曝出有机密数据外泄,明令宣布禁止员工使用ChatGPT、Google Bard、Bing等生成式AI工具。
三是产业层面。开源世界里流传着一句格言:社区重于代码,因为开源社区的聚合和放大效应比开源代码更有价值。特别是方兴未艾的大模型领域,开源的本质是协同和创新,协同是全世界所有开源方力量的协同,创新是一个技术的创新,相比于各自为战的闭源模式,开源更利于产业生态的培养和繁荣。
紫东.太初2.0宣布开源的同时,同步升级了紫东.太初开放服务平台,不仅支持公有云、私有云、混合云在内的多种部署方式,兼容昇腾、英伟达、AMD、英特尔等不同AI硬件,作为AI框架的昇思MindSpore还提供了数据中心、训练中心、模型中心、推理中心在内大模型微调套件,进一步降低了大模型的开发门槛,并通过一键式微调、低参数调优等提高了开发效率。
全模态大模型的“神奇能力”,于开发者而言不再遥不可及。
03 大模型的价值在“落地”
也许就现阶段而言,还无法为开源和闭源的胜败下定论。可对于呼唤大模型的千万家企业来说,比部署方式更重要的其实是落地,如果大模型的能力不能转变为产业价值,再美好的故事也将是泡沫。
所以在对话式机器人舆情汹涌时,不少大模型并未急于跟进,因为大模型领域的参与者们都很清楚:华而不实地凑热闹终归会被狂飙的车轮碾压,产业落地才是大模型赛道避免泡沫化的铁律。
再确切一些的话,大模型通常在大规模无标记数据上进行训练,以学习某种特征和规则,而基于大模型开发应用时,只需对大模型进行微调,就可以完成多个应用场景的任务。如果说过去的AI应用是“手工作坊”式的,在大模型的驱动下,人工智能的产业落地正在向“工厂流水线”模式演变。
至少基于昇思MindSpore AI框架的紫东.太初大模型已经印证了这一点。
比如面向开发者和个人用户,武汉人工智能研究院推出了“江城洛神”AI内容创作平台,通过紫东.太初的图像描述能力、跨模态检索能力,“江城洛神”能够自动构建AIGC的训练数据,通过文本对于生成图片的细粒度信息进行控制,例如头发的颜色、人物的表情、背景的效果、风格的定义等等。
同类平台需要输入多个提示词才能准确生图时,“江城洛神”已经通过自然语言实现了“一语成画”。鉴于紫东.太初2.0的视觉知识推理和生成,不排除会衍生出图生文、图像分类识别等个性化的新玩法。
再比如面向行业的多模态人工智能产业联合体,目的是整合产学研用各方资源,打造多模态人工智能行业应用,探索通用人工智能产业化路径,目前已经有华为、中国移动、长安汽车等66位成员参与其中。

直接的例子就是大模型在智能座舱中的应用。基于“紫东.太初”多模态大模型,长安汽车引入了元宇宙的概念,创造出了YYDS虚拟数字人。和其他车内语音助手最大的不同,“YYDS”允许用户复刻自己或亲人的形象、声音,可以捏出自己专属的语音助手,实现了千人千面的个性化需求满足。
可以找到的案例还有很多,比如紫东.太初2.0大模型在智慧法律、智慧交通、智慧政务、智慧医疗等场景中的深入落地。
或许这才是全模态大模型的正确打开方式,正在从过去的“一专一能”向“多专多能”过渡。在昇思MindSpore等开源社区的推动下,大模型不仅赋予了普通开发者使用AI的能力,也拉近了千行百业智能化转型的距离。
不出意外的话,紫东.太初2.0开创的将不只是“全模态大模型”的先河,一场以落地考验价值的产业大考悄悄拉开了帷幕。
04 写在最后
即使从2018年OpenAI的GPT算起,“大数据+大模型”的行业布道也不过才进入第五个年头,期间或许有挫折,但井喷式爆发已经是注定的事实。
而在文本、图片、音频等数据的基础上,进一步融入3D、视频、传感信号等多模态数据的紫东.太初2.0,注定了大模型进阶之路的新转折点,通过优化语音、视频和文本的融合认知以及常识计算等功能,正在让人工智能从感知世界进化为认知世界,延伸出更加强大的通用能力,不断刷新人们的想象空间。